
[ MLops Deployment & Monitoring ] Model Monitoring
Train, Test, Deploy.
그래서, 다 끝난거야?
배포 작업 이후에 어떤 것이 문제가 될 수 있을까? </br>그것을 알기 위해서는 Monitoring 작업이 필수적이다. </br> Model Monitoring 는 크게 3가지로 나뉜다.
- Data Drift
- Model Drift (Concept Drift)
- Domain Shift
그럼 대략적으로 하나씩 훑어보자.
Data Drift 의 종류
- 즉각적인 Drift
- 점진적인 Drift
- 주기적인 Drift
- 일시적인 Drift
그렇다면 Data Drift 는 어떻게 알아차릴까?
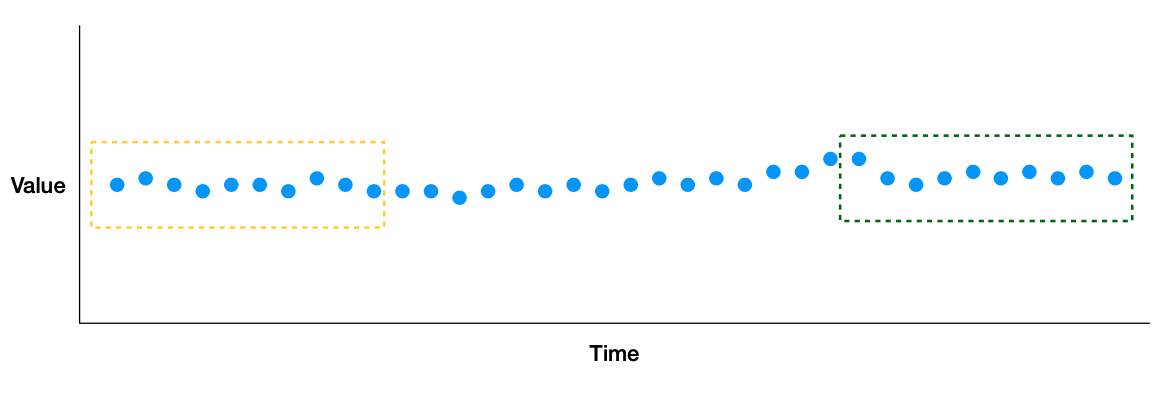
먼저 A 부분을 Healthy 한 Data라고 가정한다.
그리고 비교하고 싶은 B라는 window를 지정한다.
그 후 둘 간의 Distance를 비교한다.
비교 방법
- Rule-based distance metrics (aka, data quality)
- 통계적 방법
- KL divergence ( 가장 많이 사용함 )
- Kolmogorov-Smirnov statistic
- D_1 distance
- High Dimensional data일 경우?
- 단순히 Distance를 비교하게 되면 데이터 손실이 크다 -> 차원 축소의 Logic을 잘 거친 후에 Distance를 비교해야한다.
Evaluation Store (평가 저장소)
ML에서는 버그가 매우 조용하고 잡기 힘들다. 또한 Monitoring 을 통해서 얻을 수 있는 데이터가 다시 Model의 학습데이터로 사용될 수 있다.
따라서 Monitoring은 기존 Legacy SW보다 ML에서는 매우 중요하다.
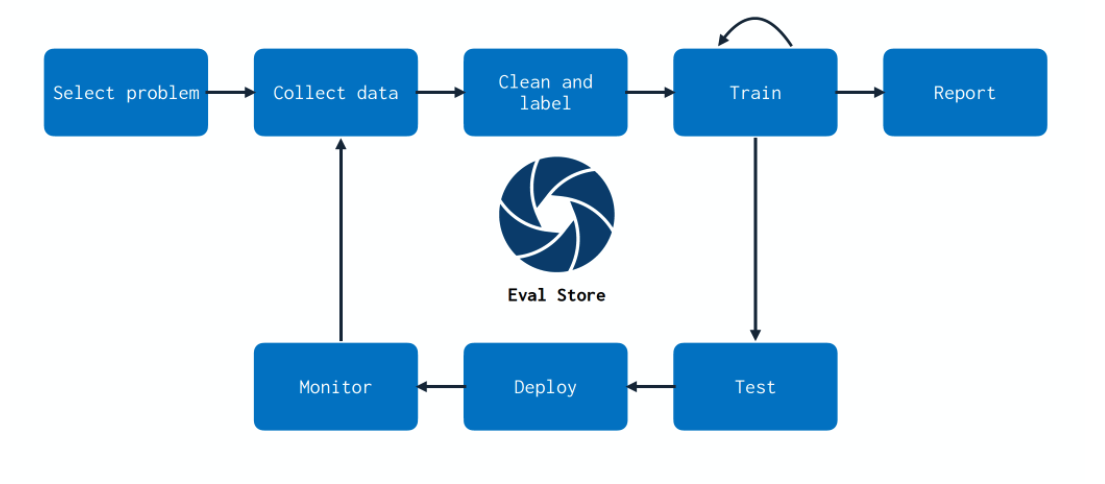
이 그림은 ML에서 Monitoring 을 통해 데이터를 어떻게 활용할건지에 대한 Flywheel 그림이다.
단순히 문제가 발생한 데이터를 버리는 것이 아니라 재가공을 진행하여 다시 학습을 시켜 Model을 한번 더 강화시키는 것이다.
참고 : https://fullstackdeeplearning.com/spring2021/lecture-11/